Главная Каталог раздела Предыдущая Оглавление Следующая Скачать в zip
Кибернетика,
или управление и связь в животном и машине
Винер
Н.
ЧАСТЬ
I. ПЕРВОНАЧАЛЬНОЕ ИЗДАНИЕ 1948 г.
III. ВРЕМЕННЫЕ РЯДЫ, ИНФОРМАЦИЯ И СВЯЗЬ
Существует
широкий класс явлений, в которых объектом наблюдения служит какая-либо числовая
величина или последовательность числовых величин, распределенные во времени.
Температура, непрерывно записываемая самопишущим термометром; курс акций на
бирже в конце каждого дня; сводка метеорологических данных, ежедневно
публикуемая бюро погоды, – все это временные ряды, непрерывные или дискретные,
одномерные или многомерные. Эти временные ряды меняются сравнительно медленно,
и их вполне можно обрабатывать посредством вычислений вручную или при помощи
обыкновенных вычислительных приборов, таких, как счетные линейки и арифмометры.
Их изучение относится к обычным разделам статистической науки.
Но не все отдают себе отчет в том, что быстро меняющиеся последовательности напряжений в телефонной линии, телевизионной схеме или радиолокаторе точно так же относятся к области статистики и временных рядов, хотя приборы, которые их комбинируют и преобразуют, должны, вообще говоря, обладать большим быстродействием и, более того, должны выдавать результаты одновременно с очень быстрыми изменениями входного сигнала. Эти приборы: телефонные аппараты, волновые фильтры, автоматические звукокодирующие устройства типа вокодера1Белловских телефонных лабораторий, схемы частотной модуляции и соответствующие им приемники – по существу [c.119] представляют собой быстродействующие арифметические устройства, соответствующие всему собранию вычислительных машин и программ статистического бюро, вместе со штатом вычислителей. Необходимый для их применения разум был вложен в них заранее, так же как и в автоматические дальномеры и системы управления артиллерийским зенитным огнем и по той же причине: цепочка операций должна выполняться настолько быстро, что ни в одном звене нельзя допустить участия человека.Все эти временные ряды и все устройства, работающие с ними, будь то в вычислительном бюро или в телефонной схеме, связаны с записью, хранением, передачей и использованием информации. Что же представляет собой эта информация и как она измеряется? Одной из простейших, наиболее элементарных форм информации является запись выбора между двумя равновероятными простыми альтернативами, например между гербом и решеткой при бросании монеты. Мы будем называть решением однократный выбор такого рода. Чтобы оценить теперь количество информации, получаемое при совершенно точном измерении величины, которая заключена между известными пределами А и В и может находиться с равномерной априорной вероятностью где угодно в этом интервале, положим А=0, В=1 и представим нашу величину в двоичной системе бесконечной двоичной дробью 0, а1, а2, а3, …, an, …, где каждое а1, а2, … имеет значение 0 или 1. Здесь
|
|
|
Мы
видим, что число сделанных выборов и вытекающее отсюда количество информации
бесконечны.
Однако
в действительности никакое измерение не производится совершенно точно. Если измерение
имеет равномерно распределенную ошибку, лежащую в интервале длины 0, b1,
b2, …, bn, …, где bk
– первый разряд, отличный от 0, то, очевидно, все решения от а1
до аk–1 и, возможно, до ak будут
значащими, а все последующие – нет. Число принятых решений, очевидно, близко к
|
|
(3.02) |
[c.120]
и это выражение мы примем за точную формулу количества информации
и за его определение.
Это
выражение можно понимать следующим образом: мы знаем априори, что
некоторая переменная лежит между нулем и единицей, и знаем апостериори, что
она лежит в интервале (а, b) внутри интервала (0, 1). Тогда количество
информации, извлекаемой нами из апостериорного знания, равно
|
|
|
Рассмотрим
теперь случай, когда мы знаем априори, что вероятность нахождения некоторой
величины между х и x+dx равна f1(x)dx,
а апостериорная вероятность этого равна f2(x)dx.
Сколько новой информации дает нам наша апостериорная вероятность?
Эта
задача, но существу, состоит в определении ширины областей, расположенных под
кривыми y=f1(x) и у=f2(x).
Заметим, что, по нашему допущению, переменная х имеет основное
равномерное распределение, т.е. наши результаты, вообще говоря, будут другими,
если мы заменим х на х3 или на какую-либо другую
функцию от х. Так как f1(x) есть плотность
вероятности, то
|
|
|
Поэтому
средний логарифм ширины области, расположенной под кривой f1(x),
можно принять за некоторое среднее значение высоты логарифма обратной величины
функции f1(x). Таким образом, разумной мерой2 количества информации,
связанного с кривой f1(x), может служить3 [c.121]
Величина,
которую мы здесь определяем как количество информации, противоположна по знаку
величине, которую в аналогичных ситуациях обычно определяют как энтропию.
Данное здесь определение не совпадает с определением Р.А. Фишера для
статистических задач, хотя оно также является статистическим определением и
может применяться в методах статистики вместо определения Фишера.
В
частности, если f1(x) постоянна на интервале (а, b)
и равна нулю вне этого интервала, то
|
|
|
Используя
это выражение для сравнения информации о том, что некоторая точка находится в
интервале (0, 1), с информацией о том, что она находится в интервале (а,
b), получим как меру разности
|
|
|
Определение,
данное нами для количества информации, пригодно также в том случае, когда
вместо переменной х берется переменная, изменяющаяся в двух или более
измерениях. В двумерном случае f1 (x, y) есть
такая функция, что
|
|
|
и
количество информации равно
|
|
|
Заметим,
что если f1(x, y) имеет вид φ(х)ψ(у)
и
|
|
|
[c.122]
|
|
|
и
|
|
|
т.е.
количество информации от независимых источников есть величина аддитивная.
Интересной
задачей является определение информации, получаемой при фиксации одной или
нескольких переменных в какой-либо задаче. Например, положим, что переменная и
заключена между х и x+dx с вероятностью
![]() ,
,
а
переменная v заключена между теми же двумя пределами с вероятностью
![]()
Сколько
мы приобретаем информации об и, если знаем, что u+v=w?
В этом случае очевидно, что u=w—v, где w
фиксировано. Мы полагаем, что априорные распределения переменных и и v
независимы, тогда апостериорное распределение переменной и
пропорционально величине
|
|
|
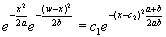 ,
,где
c1 и c2 — константы. Обе они исчезают в окончательной
формуле.
Приращение
информации об и, когда мы знаем, что w таково, каким мы его
задали заранее, равно
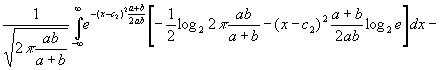
Заметим,
что выражение (3.091) положительно и не зависит от w. Оно равно половине
логарифма от отношения суммы средних квадратов переменных и и v к
среднему квадрату переменной v. Если v имеет лишь малую область
изменения, то количество информации об и, которое дается знанием суммы u+v,
велико и становится бесконечным, когда b приближается к нулю.
Пусть φ(х) и ψ(x)
– две плотности вероятностей, тогда
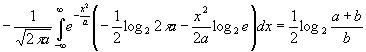
также
есть плотность вероятности и
|
|
|
Это
вытекает из того, что
|
|
|
Другими
словами, перекрытие областей под φ(х) и ψ(x)
уменьшает максимальную информацию, заключенную в сумме φ(х)+ψ(x).
Если же φ(х) есть плотность [c.124] вероятности,
обращающаяся в нуль вне (а, b), то интеграл
|
|
|
Как
и следовало ожидать, процессы, ведущие к потере информации, весьма сходны с
процессами, ведущими к росту энтропии. Они состоят в слиянии областей
вероятностей, первоначально различных. Например, если мы заменяем распределение
некоторой переменной распределением функции от нее, принимающей одинаковые
значения при разных значениях аргумента, или в случае функции нескольких
переменных позволяем некоторым из них свободно пробегать их естественную
область изменения, мы теряем информацию. Никакая операция над сообщением не
может в среднем увеличить информацию. Здесь мы имеем точное применение второго
закона термодинамики к технике связи. Обратно, уточнение в среднем
неопределенной ситуации приводит, как мы видели, большей частью к увеличению
информации и никогда – к ее потере.
Интересен
случай, когда мы имеем распределение вероятностей с n-мерной плотностью f(х1,
…, xn) по переменным (х1, …, xn)
и m зависимых переменных y1, …, ym.
Сколько информации мы приобретаем при фиксации таких т переменных? Пусть
они сперва фиксируются между пределами y1*, y1*+dy1*,
…, ym*, ym*+dym*.
Примем х1, x2, …, xn–m, у1,
y2, ..., ут за новую систему переменных.
Тогда для новой системы переменных наша функция распределения будет
пропорциональна f1(х1, …, xn)
над областью R, определенной условиями
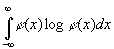
и
равна нулю вне ее. Следовательно, количество информации, полученной при
наложении условий на значения у, будет равно4
[c.125]
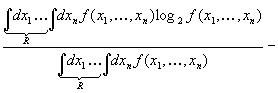
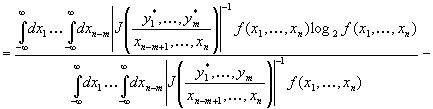
С
этой задачей тесно связано обобщение задачи, о которой говорилось по поводу
уравнения (3.091). Сколько информации в рассматриваемом случае приобретается
нами об одних только переменных х1, ..., xn–m?
Здесь априорная плотность вероятности этих переменных равна
|
|
|
а
ненормированная плотность вероятности после фиксации величин у*
будет
|
|
|
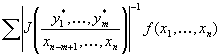
где
Σ берется по всем множествам значений (xn–m+1, …,
xn), соответствующим данному множеству значений у*.
Основываясь на этом, нетрудно записать решение нашей задачи, хотя оно и будет
несколько громоздким. Если мы примем множество (x1, …,
xn–m) за обобщенное сообщение, множество (xn–m+1,
…, xn) – за [c.126]
обобщенный шум. а величины у* – за обобщенное
искаженное сообщение, то получим, очевидно, решение обобщенной задачи выражения
(3.091).
Таким
образом, мы имеем по крайней мере формальное решение обобщения упомянутой уже
задачи о сигнале и шуме. Некоторое множество наблюдений зависит произвольным
образом от некоторого множества сообщений и шумов с известным совместным
распределением. Мы хотим установить, сколько информации об одних только
сообщениях дают эти наблюдения. Это центральная проблема техники связи. Решение
ее позволит нам оценивать различные системы связи, например системы с
амплитудной, частотной или фазовой модуляцией, в отношении их эффективности в
передаче информации. Это техническая задача, не подлежащая здесь подробному
обсуждению; уместно, однако, сделать некоторые замечания.
Во-первых,
можно показать, что если пользоваться данным здесь определением информации, то
при случайных помехах в эфире с равномерно распределенной по частоте мощностью
и для сообщения, ограниченного определенным диапазоном частот и определенной
отдачей мощности на этом диапазоне, не существует более эффективного способа
передачи информации, чем амплитудная модуляция, хотя другие способы могут быть
столь же эффективны. Во-вторых, переданная этим способом информация не
обязательно имеет такую форму, которая наиболее приемлема для слуха или для
другого данного рецептора. В этом случае специфические свойства уха и других
рецепторов должны быть учтены при помощи теории, весьма сходной с только что
изложенной. Вообще эффективное использование амплитудной модуляции или
какого-либо другого вида модуляции должно быть дополнено применением
соответствующих декодирующих устройств для преобразования принятой информации в
такую форму, которая может быть хорошо воспринята рецепторами человека или же
механическими рецепторами. Первоначальное сообщение тоже должно кодироваться,
чтобы оно занимало возможно меньше места при передаче. Эта задача была
разрешена, по крайней мере частично, когда Белловские телефонные лаборатории
разработали систему “вокодер”, а д-р К. Шеннон из этих лабораторий [c.127] представил в весьма
удовлетворительном виде соответствующую общую теорию. Так обстоит дело с
определением и методикой измерения информации. Теперь рассмотрим, каким
способом информация может быть представлена в однородной во времени форме.
Заметим, что большинство телефонных устройств и других приборов связи в
действительности не предполагает определенного начала отсчета во времени. В
самом деле, только одна операция как будто противоречит этому, но и здесь
противоречие лишь кажущееся. Мы имеем в виду модуляцию. В ее наиболее простом
виде она состоит в преобразовании сообщения f(t) в сообщение вида
f(t)sin(at+b). Однако, если мы будет рассматривать
множитель sin(at+b) как добавочное сообщение, вводимое в
аппаратуру, то, очевидно, случай модуляции подойдет под наше общее утверждение.
Добавочное сообщение, которое мы называем переносчиком, ничего не
прибавляет к скорости передачи информации системой. Вся содержащаяся в нем
информация посылается в произвольно короткий промежуток времени, и затем больше
ничего нового не передается.
Итак,
сообщение, однородное во времени, или, как выражаются профессионалы-статистики,
временной ряд, находящийся в статистическом равновесии, есть функция или
множество функций времени, входящее в ансамбль таких множеств с правильным
распределением вероятностей, не изменяющимся, если всюду заменить t на t+τ.
Иначе говоря, вероятность ансамбля инвариантна относительно группы
преобразований, состоящей из операторов Tλ которые
изменяют f(t) в f(t+λ). Группа
удовлетворяет условию
|
|
|
Следовательно,
если Ф[f(t)] – “функционал” от f(t), т.е. число,
зависящее от всей истории функции f(t), и среднее значение
f(t) по всему ансамблю конечно, то мы вправе применить
эргодическую теорему Биркгоффа из предыдущей главы и заключить, что всюду,
исключая множество значений f(t) нулевой вероятности, существует
временное среднее от Ф[f(t)], или в символах
|
|
|
[c.128]
Но это еще не все. В предыдущей главе проводилась другая теорема
эргодического характера, доказанная фон Нейманом: коль скоро некоторая система
переходит в себя при данной группе сохраняющих меру преобразований, как в
случае нашего уравнения (3.15), то, за исключением множества элементов нулевой
вероятности, каждый элемент системы входит в подмножество (быть может, равное
всему множеству), которое: 1) переходит в себя при тех же преобразованиях; 2)
имеет меру, определенную на нем самом и также инвариантную при этих
преобразованиях; 3) замечательно тем, что любая часть этого подмножества с
мерой, сохраняемой данной группой преобразований, имеет либо максимальную меру
всего подмножества, либо меру 0. Отбросив все элементы, не принадлежащие к
такому подмножеству, и используя для него надлежащую меру, мы найдем, что временное
среднее (3.16) почти во всех случаях равно среднему значению функционала Ф[f(t)]
по всему пространству функций f(t), т.е. так называемому фазовому
среднему. Стало быть, в случае такого ансамбля функции f(t),
за исключением множества случаев нулевой вероятности, мы можем найти среднее
значение любого статистического параметра ансамбля по записи любого временного
ряда ансамбля, применяя временное среднее вместо фазового. Более того, этим
путем можно найти одновременно любое счетное множество таких параметров
ансамбля, и нам нужно знать лишь прошлое одного, почти какого угодно временного
ряда ансамбля. Другими словами, если дана вся прошлая история – вплоть до
настоящего момента – временного ряда, принадлежащего к ансамблю в
статистическом равновесии, то мы можем вычислить с вероятной ошибкой, равной
нулю, все множество статистических параметров ансамбля, к которому принадлежит
ряд. До сих пор мы установили это для отдельного временного ряда, но сказанное
справедливо также для многомерных временных рядов, где вместо одной
изменяющейся величины мы имеем несколько одновременно изменяющихся величин.
Теперь
мы можем рассмотреть различные задачи, относящиеся к временным рядам.
Ограничимся случаями, в которых все прошлое временного ряда может быть задано
счетным множеством величин. Например, для [c.129]
довольно широкого класса функций f(t) (–∞
< t < ∞) функция f(t) полностью определена,
если известно множество величин
|
|
|
Пусть
теперь А – некоторая функция от будущих значений t, т.е. от
значений аргумента, больших нуля. Тогда мы можем определить совместное
распределение величин (a0, a1, ..., аn,
A) из прошлого одного, почти любого временного ряда, если множество
функций f берется в самом узком возможном смысле. В частности, если даны
все a0, ..., аn, то мы можем найти
распределение функции А. Здесь мы прибегаем к известной теореме Никодима
об условных вероятностях. Та же теорема гарантирует нам, что это распределение
при весьма общих условиях стремится к пределу, когда п→∞, и
этот предел даст нам полные сведения относительно распределения любой будущей
величины. Мы можем таким же образом определить по известному прошлому
совместное распределение значений любого множества будущих величин или любого
множества величин, зависящих от прошлого и от будущего. Если теперь нам дана
некоторая подходящая интерпретация “наилучшего значения” статистического
параметра или множества статистических параметров – например, в смысле
математического ожидания, или медианы, или моды, – то мы можем вычислить это
значение из известного распределения и получить предсказание, удовлетворяющее
любому желательному критерию надежности предсказания. Мы можем численно оценить
качество предсказания, применяя какой угодно статистический показатель
качества: среднеквадратическую ошибку, максимальную ошибку, среднюю абсолютную
ошибку и т.д. Мы можем вычислить количество информации о любом статистическом
параметре или множестве статистических параметров, которое дает нам фиксация
прошлого. Можно даже вычислить количество информации о всем будущем после
определенного момента, даваемое нам знанием прошлого. Правда, если этот момент
– настоящее, то, вообще говоря, мы будем знать о нем из прошлого, и наше знание
настоящего будет содержать бесконечно много информации. [c.130]
Другой интересной проблемой является проблема многомерных
временных рядов, в которых мы точно знаем лишь прошлое нескольких составляющих.
Распределение величины, зависящей от более богатого прошлого, может изучаться
методами, весьма близкими к уже рассмотренным. В частности, нам может
понадобиться узнать распределение значений другой составляющей или множества
значений других составляющих в некоторый момент прошлого, настоящего или
будущего. К этому классу относится и общая задача о волновом фильтре. Даны
сообщение и шум, скомбинированные некоторым образом в искаженное сообщение,
прошлое которого нам известно. Нам известно также статистическое совместное
распределение сообщения и шума как временных рядов. Мы ищем распределение
значений сообщения в данный момент прошлого, настоящего или будущего. Затем мы
разыскиваем оператор, который, будучи применен к прошлому искаженного
сообщения, восстановит истинное сообщение наилучшим образом, в данном
статистическом смысле. Мы можем также искать статистическую оценку какой-либо
меры ошибок в нашем знании сообщения. Наконец, мы можем искать количество
информации, которым располагаем в сообщении.
Особенно
простым и важным является ансамбль временных рядов, связанный с броуновым
движением. Броуновым движением называется движение частицы газа, толкаемой
случайными ударами других частиц под действием теплового возбуждения. Теория
его была разработана многими исследователями, в частности Эйнштейном,
Смолуховским, Перреном и автором5. Если только мы не
спускаемся по шкале времени до столь малых промежутков, что становятся
различимыми отдельные удары частиц по данной частице, броуново движение
обнаруживает любопытное явление недифференцируемости. Средний квадрат
перемещения частицы в данном направлении за данный промежуток времени
пропорционален длине этого промежутка, а перемещения за [c.131] последовательные промежутки времени совершенно не
коррелируются между собой. Это вполне согласуется с физическими наблюдениями.
Если мы нормируем шкалу броунова движения соответственно шкале времени и будем
рассматривать только одну координату х, положив x(t)=0
для t=0, то вероятность того, что при 0≤t1≤t2…≤tn
частицы находятся между х1 и x1+dx1
в момент t1 между х2 и x2+dx2
в момент t2, ..., между xп и xп+dхп
в момент tn равна
|
|
|
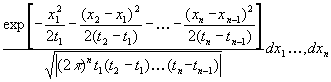 .
.Исходя
из создаваемой этим системы вероятностей, вполне однозначной, мы можем ввести на
множестве путей, соответствующих различным возможным броуновым перемещениям,
такой параметр α, лежащий между 0 и 1, что: 1) каждый путь будет функцией x(t,α),
где х зависит от времени t и параметра распределения α и 2)
вероятность данному пути находиться в данном множестве S будет равна
мере множества значений α, соответствующих путях, находящимся в S.
Поэтому почти все пути будут непрерывными и недифференцируемыми.
Весьма
интересен вопрос об определении среднего значения произведения x(t,
α), …, x(tn, α) относительно α. Это
среднее равно
|
|
|
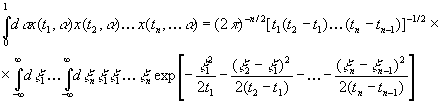
при
условии 0 ≤t1 ≤…≤ tn.
Положим
|
|
|
[c.132]
где λk,1+λk,2+…+λk,n=n.Тогда
выражение (3.19) примет значение
|
|
|
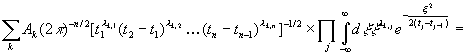
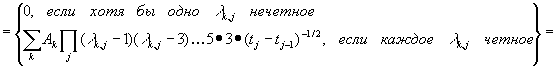
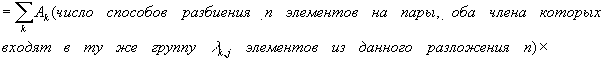
Здесь
первая сумма берется по j; вторая – по всем способам разбиения п
элементов на пары в группах, включающих соответственно λk,1, …,
λk,n элементов; произведение – по парам значений k
и q, где λk,1 элементов среди выбранных tk
и tq равны t1, λk,2
элементов равны t2 и т.д. Отсюда сразу же следует
|
|
|
[c.133]
где сумма берется по всем разбиениям величин t1,
..., tn на различные пары, произведение – по всем парам в
каждом разбиении. Другими словами, если нам известны средние значения попарных
произведений величин x(tj, α), то нам известны и
средние значения всех многочленов от этих величин и, следовательно, их полное статистическое
распределение.
До сих пор мы рассматривали броуновы перемещения x
(tj,α), в которых t положительно. Положив
|
|
|
где
α и β имеют независимые равномерные распределения в интервале (0, 1),
получим распределение для ξ(t, α, β), где t
пробегает всю бесконечную действительную ось. Существует хорошо известный
математический прием отобразить квадрат на прямолинейный отрезок таким образом,
что площадь преобразуется в длину. Надо лишь записать координаты квадрата в
десятичной форме
|
|
|
и
положить
|
|
и
мы получим искомое отображение, являющееся взаимно однозначным почти для всех
точек как прямолинейного отрезка, так и квадрата. Используя эту подстановку,
введем
|
|
(3.25) |
Теперь
мы хотим определить в некотором подходящем смысле
|
|
|
Сразу
приходит мысль определить указанное выражение как интеграл Стильтьеса6, но это встречает [c.134] препятствие в том, что
ξ представляет собой весьма нерегулярную функцию от t. Однако если К
приближается достаточно быстро к нулю при t→± ∞ и является
достаточно гладкой функцией, то разумно положить
|
|
|
При
этих условиях мы формально получим
|
|
|
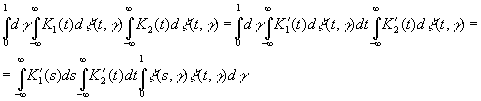
Если
теперь t и s имеют противоположные знаки, то
|
|
|
а
если они одного знака и |s|<|t|, то
|
|
|
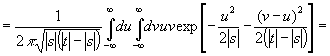
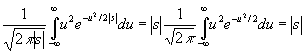
[c.135]
|
|
|
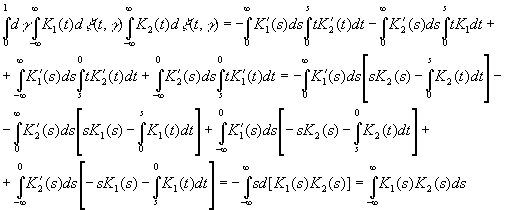
В
частности,
|
|
|
|
|
|
[c.136]
где сумма берется по всем разбиениям величин τ1,
…, τn на пары, а произведение – по парам в каждом
разбиении. Выражение
|
|
|
изображает
очень важный ансамбль временных рядов по переменной t, зависящих от
некоторого параметра распределения γ. Доказанное нами равносильно
утверждению, что все моменты и, следовательно, все статистические параметры
этого распределения зависят от функции
|
|
|
представляющей
собой известную в статистике автокорреляционную функцию со сдвигом τ. Таким
образом, распределение функции f(t, γ) имеет те же
статистики, что и функция f(t+t1, γ); и
действительно, можно доказать, что если
|
|
(3.36) |
то
преобразование параметра γ в Г сохраняет меру. Другими словами, наш
временной ряд f(t, γ) находится в статистическом равновесии.
Далее,
если мы рассмотрим среднее значение для
|
|
|
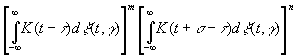
то
оно состоит в точности из членов выражения
|
|
|
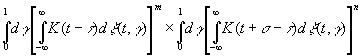
[c.137]
и из конечного числа членов, имеющих множителями степени
выражения
|
(3.39) |
если
последнее стремится к нулю при σ→∞, то (3.38) будет пределом
выражения (3.37). Другими словами, распределения функций f(t,
γ) и f(t+σ, γ) становятся асимптотически
независимыми, когда σ→∞. Более общим, но совершенно
аналогичным рассуждением можно показать, что одновременное распределение функций
f(t1, γ), ..., f(tn,
γ) и функций f(σ+s1, γ), …, f(σ+sm,
γ) стремится к совместному распределению первого и второго множества,
когда σ→∞. Другими словами, если F[f (t,
γ)] – любой ограниченный измеримый функционал, т.е. величина, зависящая от
всего распределения значений функции f(t, γ) от t, то
для него должно выполняться условие
|
|
|
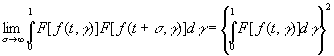 .
.Если
F[f (t, γ)] инвариантен при сдвиге по t и
принимает только значения 0 или 1, то
|
|
|
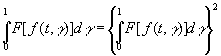 ,
,т.е.
группа преобразований f(t, γ) в f(t+σ,
γ) метрически транзитивна. Отсюда следует, что если F[f
(t, γ)] – любой интегрируемый функционал от f как функции от
t, то по эргодической теореме
|
|
|
[c.138]
для всех значений γ, исключая множество нулевой меры.
Таким образом, мы почти всегда можем определить любой статистический параметр
такого временного ряда (и даже любого счетного множества статистических
параметров) из прошлой истории одного только параметра. В самом деле, если для
такого временного ряда мы знаем
|
|
|
то
мы знаем Ф(t) почти во всех случаях и располагаем полным статистическим
знанием о временном ряде.
Некоторые
величины, зависящие от временного ряда такого рода, обладают интересными
свойствами. В частности, интересно знать среднее значение величины
|
|
|
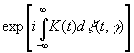
Формально
мы можем записать его в виде
|
|
|
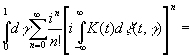
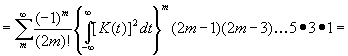
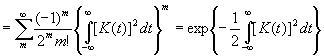 .
.Весьма
интересная задача – попытаться построить возможно более общий временной ряд из
простых рядов броунова движения. При таких построениях, как подсказывает пример
рядов Фурье, разложения типа (3.44) составляют удобные строительные блоки. В
частности, исследуем временные ряды специального вида:
|
|
|
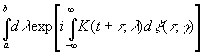
[c.139]
Предположим, что нам известна функция ξ(τ, γ),
а также выражение (3.46). Тогда при t1>t2
находим, как в (3.45),
|
|
|
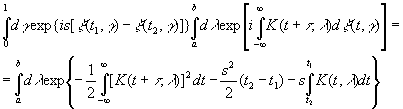
Умножив
на
![]()
и
положив s(t2–t1)=iσ,
получим при t2→t1
|
|
|
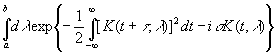
Примем
K(t1, λ) за новую независимую переменную μ
и, решая относительно λ, получим
|
|
(3.49) |
Тогда
выражение (3.48) будет иметь вид
|
|
|
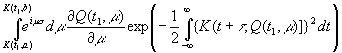
Отсюда
преобразованием Фурье можно найти
|
|
|
как
функцию от μ, коль скоро μ лежит между K(t1,
a) и K(t1, b). Интегрируя эту функцию по
μ, найдем
|
|
|
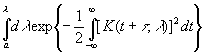
[c.140]
как функцию от K(t1, λ) и t1.
Иначе говоря, существует известная функция F (u, v), такая, что
|
|
|
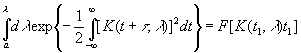
Поскольку
левая часть этого равенства не зависит от t1, мы можем обозначить
ее через G(λ) и положить
|
|
(3.54) |
Здесь
F – известная функция, и ее можно обратить относительно первого
аргумента, положив
|
|
(3.55) |
где
H – также известная функция. Отсюда
|
|
|
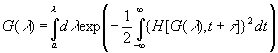
Тогда
выражение
|
|
|
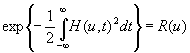
будет
известной функцией и
|
|
|
откуда
|
|
|
или
|
|
|
Входящую
в это выражение константу можно определить из соотношения
|
|
(3.61) |
или
|
|
(3.62) |
Очевидно,
что если а конечно, то безразлично, какое значение мы ему дадим; в самом
деле, наш оператор не [c.141] изменится от прибавления одной и той же величины ко всем
значениям λ. Поэтому можно взять а=0. Таким образом, мы определили
λ как функцию от G и, следовательно, G – как функцию от
λ. Из (3.55) следует, что мы тем самым определили K(t,
λ). Для завершения расчетов нам нужно только найти b. Это число
можно определить сравнением выражений
|
|
(3.63) |
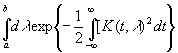
и
|
|
|
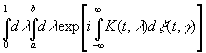 .
.Таким
образом, если при некоторых условиях, которые еще остается точно сформулировать,
временной ряд допускает запись в виде (3.46) и известна функция ξ(t,
γ) то мы можем определить функцию K(t, λ) в (3.46) и
числа а и b с точностью до неопределенной константы, прибавляемой
к а, λ и b. Не возникает особых трудностей при b→+∞,
также не слишком сложно распространить эти рассуждения на случай а→
–∞. Конечно, предстоит проделать еще немалую работу, рассматривая задачу
обращения функций в случае, когда результаты не однозначны, и общие условия
справедливости соответствующих разложений. Тем не менее мы по крайней мере
сделали первый шаг к решению задачи приведения обширного класса временных рядов
к каноническому виду, что чрезвычайно важно для конкретного формального
применения теорий предсказания и измерения информации, намеченных выше в этой
главе.
Имеется,
однако, одно очевидное ограничение, которое мы должны устранить из этого
наброска теории временных рядов, а именно необходимость знать ξ(t,
γ), и временной ряд, который мы разлагаем в виде (3.46). Вопрос ставится
так: при каких условиях временной ряд с известными статистическими параметрами
можно представить как ряд, определяемый броуновым движением, или по крайней
мере как предел (в том или ином смысле) временных рядов, определяемых броуновым
движением? Мы ограничимся временными рядами, [c.142]
обладающими свойством метрической транзитивности
и даже следующим более сильным свойством: если брать интервалы времени
фиксированной длины, но отдаленные друг от друга, то распределения любых
функционалов от отрезков временного ряда в этих интервалах приближаются к
независимости по мере того, как интервалы отдаляются друг от друга7.
Соответствующая теория уже излагалась автором.
Если
K(t) – достаточно непрерывная функция, то можно показать, что
нули величины
|
|
|
по
теореме М. Каца, почти всегда имеют определенную плотность и что эта плотность
при подходящем выборе К может быть сделана сколь угодно большой. Пусть
выбрано такое КD, что плотность равна D.
Последовательность нулей величины
![]() ,
,
Пусть
теперь T(t, μ) – произвольный временной ряд от непрерывной
переменной t, а μ – параметр распределения временных рядов,
изменяющийся равномерно в интервале (0, 1). Пусть далее
|
|
(3.66) |
где
Zn – нуль, непосредственно предшествующий моменту t.
Можно показать, что, каково бы почти ни было μ, для любого конечного
множества значений t1, t2, …, tv
переменной х одновременное распределение величин TD(tk,
μ, γ) (k=1, 2, ..., v) при D→∞ будет
приближаться к одновременному распределению величин T(tk,
μ) для тех же tk при D→∞. Но TD(tk,
μ, γ) полностью определяется величинами tk, μ,
D. Поэтому вполне уместно попытаться выразить TD(tk,
μ, γ) [c.143] для
данного D и данного μ, либо прямо в виде (3.46), либо некоторым
образом в виде временного ряда, распределение которого является пределом (в указанном
свободном смысле) распределении этого типа.
Следует
признать, что все это изображает скорее программу на будущее, чем уже
выполненную работу. Тем не менее эта программа, по мнению автора, дает
наилучшую основу для рационального, последовательного рассмотрения многих задач
в области нелинейного предсказания, нелинейной фильтрации, оценки передачи
информации в нелинейных системах и теории плотного газа и турбулентности. К ним
принадлежат, быть может, самые острые задачи, стоящие перед техникой связи.
Перейдем
теперь к задаче предсказания для временных рядов вида (3.34). Мы замечаем, что
единственным независимым статистическим параметром такого временного ряда
является функция Ф(t), определенная формулой (3.35). Это значит, что
единственной значащей величиной, связанной с K(t),
является
|
|
|
Конечно,
здесь К – величина действительная.
Применяя
преобразование Фурье, положим
|
|
Если
известно K(s), то известно k(ω), и обратно.
Тогда
|
|
|
Таким
образом, знание Ф(t) равносильно знанию k(ω)k(–ω).
Но поскольку K(s) действительно, то
|
|
|
откуда
![]() . Следовательно, |k(ω)|2
есть известная функция, а потому действительная часть log|k(ω)|
также есть известная функция. [c.144]
. Следовательно, |k(ω)|2
есть известная функция, а потому действительная часть log|k(ω)|
также есть известная функция. [c.144]
Если записать8
|
|
(3.71) |
то
нахождение функции K(s) эквивалентно нахождению мнимой части log k(ω).
Это задача неопределенная, если не наложить дальнейшего ограничения на k(ω).
Налагаемое ограничение будет состоять в том, что log k(ω) должен
быть аналитической функцией и иметь достаточно малую скорость роста
относительно ω в верхней полуплоскости. Для выполнения этого условия
предположим, что k(ω) и [k(ω)]–1 возрастают
вдоль действительной оси алгебраически. Тогда [F(ω)]2
будет четной и не более, чем логарифмически бесконечной функцией, и будет
существовать главное значение Коши9 для
|
|
|
Преобразование,
определяемое выражением (3.72), называется преобразованием Гильберта; оно
изменяет cos λω в sin λω и sin λω
в –cos λω. Следовательно,
есть
функция вида
|
|
|
и
удовлетворяет требуемым условиям для log |k(ω)| в нижней
полуплоскости.
Если теперь положить
|
|
(3.74) |
то
можно показать, что при весьма общих условиях функция K(s),
определяемая формулой (3.68), будет обращаться в нуль для всех отрицательных
аргументов. Таким образом,
|
|
|
[c.145]
С другой стороны, можно показать, что 1/k(ω)
записывается в виде
|
|
|
где
значения Nn определены подходящим образом, и что при этом
можно получить
|
|
|
Здесь
значения Qn должны удовлетворять формальному условию
|
|
|
В
общем случае будем иметь
|
|
|
а
если ввести по образцу соотношения (3.68)
|
|
|
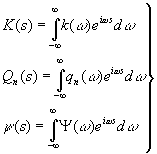 ,
,то
|
|
(3.81) |
Следовательно,
|
|
|
Этот
вывод мы используем для того, чтобы получить оператор предсказания в форме,
связанной не со временем, а с частотой. [c.146]
Таким образом, прошлое и настоящее функции ξ(t,
γ), или точнее “дифференциала” dξ(t, γ),
определяют прошлое и настоящее функции f(t, γ), и обратно.
Если
теперь А >0, то
|
|
|
Здесь
первый член последнего выражения зависит от области изменения dξ(t,
γ), в которой, зная лишь f(σ, γ) для σ≤,
сказать ничего нельзя, и совершенно не зависит от второго члена. Его
среднеквадратическое значение равно
|
|
|
и
эта формула дает все статистическое знание о нем. Можно показать, что первый член
имеет гауссово распределение с этим среднеквадратическим значением. Последнее
равно ошибке наилучшего возможного предсказания функции f(t+A,
γ).
Само
же наилучшее возможное предсказание выражается вторым членом в (3.83):
|
|
Если
теперь положим
|
|
|
[c.147]
и применим оператор (3.85) к eiωt,
получив
|
|
|
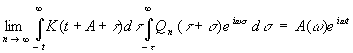 ,
,то
найдем, подобно (3.81), что
|
|
|
Это
и есть частотная форма наилучшего оператора предсказания.
Задача
фильтрации в случае временных рядов типа (3.34) тесно связана с задачей
предсказания. Пусть сумма сообщения и шума имеет вид
|
|
|
а
сообщение имеет вид
|
|
|
где
γ и δ распределены независимо в интервале (0, 1). Тогда предсказуемая
часть функции m(t+a), очевидно, равна
|
|
|
а
среднеквадратическая ошибка предсказания равна
|
|
|
Допустим,
кроме того, что нам известны следующие величины:
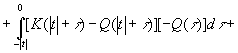
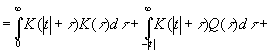
Преобразование Фурье для этих величин соответственно равно
|
|
|
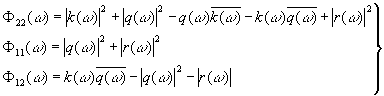
где
|
|
|
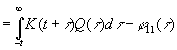
то
есть
|
|
(3.908) |
и
|
|
(3.909) |
![]() .
.
Теперь
мы можем определить k(ω) из (3.908), как прежде определили k(ω)
из (3.74). Здесь мы принимаем
|
|
В
результате
|
|
|
и
|
|
|
Таким
образом, наилучшее определение функции m(t) с наименьшей
среднеквадратической ошибкой есть
|
|
|
[c.150]
Сравнивая это с уравнением (3.89) и пользуясь рассуждениями,
подобными тем, посредством которых было получено (3.88), заключаем, что
оператор для m(t)+n(t), дающий “наилучшее”
представление функции m(t+a), имеет при записи в частотной шкале
следующий вид:
|
|
|
Этот
оператор служит характеристическим оператором устройства, которое в
электротехнике называют волновым фильтром. Величина а есть фазовое
отставание фильтра. Она может быть положительной или отрицательной; если
она отрицательна, то а называется фазовым опережением. Прибор,
соответствующий формуле (3.913), может быть построен с какой угодно точностью.
Подробности его конструкции нужны более для инженера-электрика, чем для
читателя этой книги. Их можно найти в соответствующей литературе10.
Среднеквадратическая
ошибка фильтрации (3.902) может быть представлена как сумма
среднеквадратической ошибки фильтрации для бесконечного фазового отставания
|
|
|
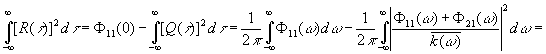
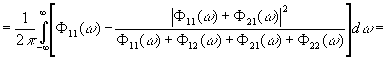
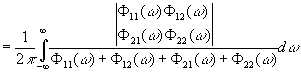
[c.151]
|
|
|
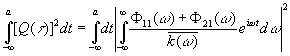 ,
,зависящего
от фазового отставания. Мы видим, что среднеквадратическая ошибка фильтрации есть
монотонно убывающая функция фазового отставания.
Другим
интересным вопросом в случае сообщений и шумов, порождаемых броуновым
движением, является скорость передачи информации. Рассмотрим для простоты случай,
когда сообщение и шум независимы, т.е. когда
|
|
(3.916) |
Рассмотрим
в этом случае функции
|
|
|
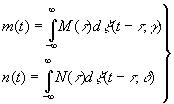 ,
,где
γ и σ распределены независимо. Пусть нам известна сумма m(t)+n(t)
в интервале (–А, А). Сколько у нас тогда информации об m(t)?
Заметим, что, по эвристическому суждению, это количество информации не должно
слишком отличаться от количества информации о функции
которым
мы располагаем, когда нам известны все значения выражения
|
|
|
где
γ и σ имеют независимые распределения. Можно, однако, показать, что п-й
коэффициент Фурье для выражения (3.918) имеет гауссово распределение,
независимое от всех других коэффициентов Фурье, и что его [c.152] среднеквадратическое значение пропорционально величине
|
|
|
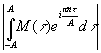
Следовательно,
в силу (3.09) полное количество информации об М равно
|
|
|
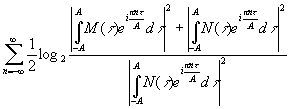 ,
,а
временная плотность передачи энергии равна этой величине, деленной на 2А.
Если А→∞, то выражение (3.921) стремится к
|
|
|
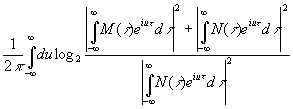 .
.Именно
этот результат и был получен автором и Шенноном для скорости передачи
информации в рассматриваемом случае. Как видим, эта величина зависит не только
от ширины полосы частот, которой мы располагаем для передачи сообщения, но и от
уровня шума. В действительности она обнаруживает прямую связь с аудиограммами,
применяемыми для измерения величины слуха и потери его у данного индивидуума. В
аудио-грамме абсциссой служит частота, ординатой нижней границы – логарифм
порога слышимой силы звука (мы можем назвать его логарифмом внутреннего шума
принимающей системы), а ординатой верхней границы – логарифм наибольшей силы
звука, которую система может пропустить. Площадь между ними, представляющая
величину такой же размерности, как выражение (3.922), принимается за меру скорости
передачи информации, с которой ухо способно справиться. [c.153]
Теория сообщений, линейно зависящих от броунова движения,
имеет много важных вариантов. Основными являются формулы (3.88), (3.914) и
(3.922), разумеется, вместе с определениями, необходимыми для их понимания.
Существует ряд вариантов этой теории. Прежде всего она дает нам наилучший
возможный синтез предсказывающих устройств и волновых фильтров в случае, когда
сообщения и шумы представляют собой реакции линейных резонаторов на броуновы движения,
однако и в значительно более общих случаях она обеспечивает некоторый возможный
синтез предсказывающих устройств и фильтров. Последние, правда, не будут иметь
абсолютно наилучшей конструкции, но, во всяком случае, позволят свести к
минимуму среднеквадратическую ошибку предсказания при использовании линейных
устройств. Однако, вообще говоря, найдутся такие нелинейные устройства, которые
будут работать лучше, чем любые линейные устройства.
Кроме
того, выше мы рассматривали простые временные ряды, в которых от времени
зависит лишь одна числовая переменная. Существуют также многомерные временные
ряды, где несколько таких переменных зависят все вместе от времени; именно
многомерные ряды имеют наибольшее значение в экономических науках, метеорологии
и т.п. Полная карта погоды Соединенных Штатов, составляемая ежедневно, есть
такой временной ряд. В этом случае нам нужно одновременно выразить несколько
функций через частоту, причем квадратические величины, такие, как выражение
(3.35) или |k(ω)|2 в рассуждениях после формулы (3.70),
заменяются множествами пар величин, т.е. матрицами. Задача определения
функции k(ω) через |k(ω)|2 с выполнением
некоторых добавочных условий в комплексной плоскости становится теперь гораздо
труднее, особенно ввиду того, что умножение матриц не является перестановочной
операцией. Тем не менее задачи, относящиеся к этой многомерной теории, были
решены, по крайней мере частично, Крейном и автором.
Многомерная
теория представляет собой усложнение предыдущей теории. Существует, кроме того,
другая близкая теория, которая является ее упрощением. Эта теория предсказания,
фильтрации и количества информации в дискретных временных рядах. Такой ряд [c.154]
представляет собой последовательность функций fn(α)
параметра α, где n пробегает все целочисленные значения от –∞
до ∞. Величина α, как и раньше, служит параметром распределения, и
можно по-прежнему считать, что этот параметр изменяется равномерно в интервале
(0, 1). Говорят, что временной ряд находится в статистическом равновесии,
если замена п на n+v (v – целое число) равносильна
сохраняющему меру преобразованию в себя интервала (0, 1), пробегаемого
параметром α.
Теория
дискретных временных рядов во многих отношениях проще теории непрерывных рядов.
Гораздо легче, например, свести их к последовательности независимых выборов.
Каждый член (в случае перемешивания) можно представить как комбинацию
предшествующих членов с некоторой величиной, не зависящей от всех
предшествующих членов и равномерно распределенной в интервале (0, 1), и
последовательность этих независимых коэффициентов взять вместо броунова
движения, столь важного для непрерывных рядов.
Если
fn(α) – временной ряд, находящийся в статистическом
равновесии и метрически транзитивный, то его коэффициент автокорреляции будет
равен
|
|
|
и
мы будем иметь
|
|
|
почти
для всех α. Положим
|
|
|
или
|
|
|
[c.155]
|
|
|
|
|
|
|
|
(3.929) |
Тогда
при очень общих условиях k(ω) будет граничным значением на единичном
круге для функции без нулей и особых точек внутри единичного круга; (а является
здесь углом. Отсюда
|
|
(3.930) |
Если
теперь за наилучшее линейное предсказание функции fn(α)
с опережением v принимается
|
|
|
то
|
|
|
Это
выражение аналогично выражению (3.88). Заметим, что если положить
|
|
то
|
|
|
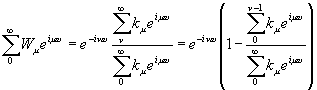
[c.156]
Из нашего способа образования k(ω) видно, что для
весьма широкого класса случаев мы вправе положить
|
|
|
Тогда
уравнение (3.934) принимает вид
|
|
|
В
частности, при v=l
|
|
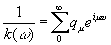 ,
,или
|
|
(3.938) |
Таким
образом, при предсказании на один шаг вперед наилучшим значением для fn+1(α)
будет
|
|
|
последовательным
же предсказанием по шагам мы можем решить всю задачу линейного предсказания для
дискретных временных рядов. Как и в непрерывном случае, это будет наилучшим
возможным предсказанием относительно любых методов, если
|
|
|
Переход
от непрерывного случая к дискретному в задаче фильтрации совершается примерно
таким же путем. Формула (3.913) для частотной характеристики наилучшего фильтра
принимает вид
|
|
|
где
все члены имеют тот же смысл, что и в непрерывном случае, за исключением того,
что все интегралы по ω и u [c.157]
имеют пределы от –π до π, а не от –∞ до
∞ и вместо интегралов по t берутся дискретные суммы по v.
Фильтры для дискретных временных рядов представляют собой обычно не столько
физически осуществимые устройства для применения в электрической схеме, сколько
математические процедуры, позволяющие статистикам получать наилучшие результаты
со статистически несовершенными данными.
Наконец,
скорость передачи информации дискретным временным рядом вида
|
|
|
при
наличии шума
|
|
|
где
γ и δ независимы, будет точным аналогом выражения (3.922), а именно:
|
|
|
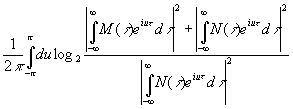 ,
,где
на интервале (–π, π) выражение
|
|
|
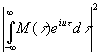
изображает
распределение мощности сообщения по частоте, а выражение
|
|
|
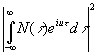
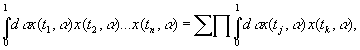{kind=link}
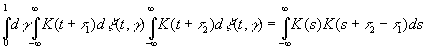{kind=link}
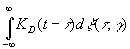{kind=link}
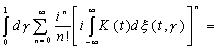{kind=link}
![[c.149]](Vinkib3.files/Image414.gif){kind=link}
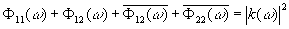{kind=link}
{kind=link}
изображает
распределение мощности шума.
Изложенные
здесь статистические теории предполагают полное знание прошлого наблюдаемых
нами временных рядов. Во всех реальных случаях мы должны довольствоваться
меньшим, поскольку наши наблюдения не распространяются в прошлое до
бесконечности. Разработка нашей теории за пределы этого [c.158] ограничения требует расширения
существующих методов выборки. Автор и другие исследователи сделали первые шаги
в этом направлении. Это связано со всеми сложностями применения закона Бейеса
либо тех терминологических ухищрений теории правдоподобия11,
которые на первый взгляд устраняют необходимость в применении закона Бейеса, но
в действительности лишь перелагают ответственность за его применение на
статистика-практика или на лицо, использующее в конце концов результаты,
полученные статистиком-практиком. Тем временем статистик-теоретик может вполне
честно утверждать, что все сказанное им является совершенно строгим и
безупречным.
В заключение этой главы мы коснемся современной квантовой механики, на которой сильнее всего сказалось вторжение теории временных рядов в современную физику. В ньютоновой физике последовательность физических явлений полностью определяется своим прошлым, и в частности, указанием всех положений и импульсов в какой-либо один момент. В полной гиббсовской теории, при точном определении многомерного временного ряда всей Вселенной, знание всех